AWS Platform Guide
Security Incident Response Plan Template
<APPLICATION / SYSTEM NAME AS IT APPEARS IN NETREG>
<DATE>
Response Introduction
This is the Security Incident Response Plan for <APPLICATION/SYSTEM NAME> that documents the procedures for responding to a security incident.
The goal of the Security Incident Response Plan is to provide tools to help technical staff who are responsible for supporting systems to effectively respond to security incidents, and to minimize any negative impact to institutional operations through a set of detection, analysis and recovery activities.
System Overview
<Provide a summary of the covered system’s business and technical functions. If the information is maintained in other documents, provide links to those documents. Include the name of the application/system as it is registered>
TODO: add a starter list of artifacts that thoughtbot typically delivers.
Architecture Model
<Attach a high-level diagram of the application/system data flow and data storage, including all interconnected system names and networks (e.g., public vs. private)>
System Hardware Inventory
<Insert hardware inventory of covered devices, e.g., provide a link to the inventory file>
Audit Logging
<Insert details of the application system audit logging processes. Include details about where the log files are located, as well as a brief description of the events captured in each log file>
TODO: Insert standard thoughtbot approach to logging and alerting.
Glossary
Breach - A breach is defined as a security incident that requires notification to affected individuals, where the protected data of the affected individual was, or is reasonably believed to have been, accessed by an unauthorized person.
Event - An event is any observable occurrence on a system or network, e.g. system login, file creation or application transaction.
Security Incident - An event, or series of events, that violates, or is about to violate, campus policies and standards.
System Contacts
The <APPLICATION/SYSTEM NAME> Incident Response Team includes the following staff:
| Incident Management Team | Phone Number | |
|---|---|---|
The Incident Management Team are engineers who have technical knowledge of the application/system and full understanding of the Security Incident Response Plan. The first point of contact should be a designated On-Call Engineer.
<If there is an on-call rotation, insert instructions on how to access the rotation>
| Client Contact | Phone Number | |
|---|---|---|
Client Contacts ** are people who understands the business impact of the system and its unavailability, and can make decisions on behalf of the client team.
<Insert other points of contact and their information, and/or instructions for hierarchy of communication>
Incident Response Procedures
Guideline
<Example of response flowchart below. Insert one that is relevant to your team>
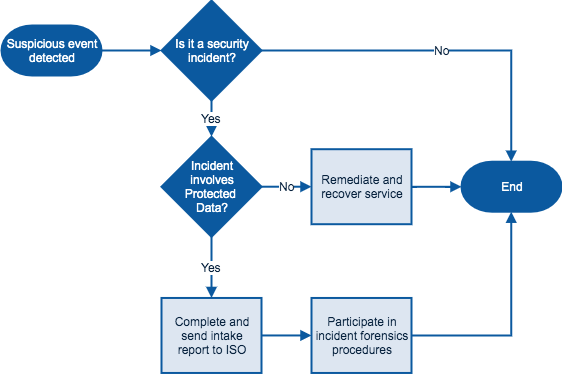
The high level incident response steps can be summarized in the flowchart above. The sections below outline detailed procedures for each step.
Step 1: Detection
The monitoring tools and alert systems are set up to notify the proper contacts automatically should suspicious events occur. All events reported by end users of the application/system should be directed to the Incident Management Team, starting with a designated On-Call Engineer.
The On-Call Engineer will then notify others within the Client and thoughtbot teams as laid out in the System Contact section.
Step 2: Response
The On-Call Engineer (with support from the Incident Management Team, if needed) should start by determining whether suspicious system events constitute a Security Incident.
<Steps can include, but not limited to the following. Edit as needed>
- Gather information about incident: sequence of events, including any unexpected observations and/or the actions taken so far
- List the devices/systems that are affected, their functions, and the number of users that might be impacted
- Review the evidence of compromise (email samples, screenshots, suspicious files, etc.)
- Document any observations and decisions made based upon discussion or evidence analysis.
The rationale used to determine whether the suspicious events constitute a Security Incident must be documented.
If the suspicious events are confirmed to be a Security Incident, continue to the next step to Assess Initial Impact.
If the suspicious events are one-time computer glitches or user misjudgement, and does not fit the definition of a Security Incident, document the decision and close the incident response process.
Step 3: Resolution
The Incident Management Team should proceed with the following steps to return affected systems to a normal operational state:
<Insert relevant steps. Some examples below:>
- Change passwords that are affected
- If available, collect any operating system or application level audit logs to capture events that show what data was accessed, when the suspicious event started/stopped, and what action was performed
- Repair affected system
Examples of compromises and the corresponding remediation procedures are provided below. Note that depending on the nature of compromise, a combination of remediation procedures may be needed to fully address the cause:
| Scenario | Resolution Procedures |
|---|---|
<Fill in common scenarios and procedures. Should be reviewed/updated after each incident post-mortem>
Step 4: Analysis
After the system has been returned to an operational state, the persons listed below should gather for a blameless post-mortem to assess the response. They should thoroughly document actions performed and observations made during the incident response process, and any improvements needed before the next incident.
<insert persons for post-mortem>
Step 5: Readiness
If the post-mortem resulted in any action items to improve the process of responding to the next incident, follow up on these items, such as:
- Update the runbook
- Implement prevention plans
- Improve monitoring/alerting
AWS Platform Guide
The guide for building and maintaining production-grade Kubernetes clusters with built-in support for SRE best practices.
Source available on GitHub.