AWS Platform Guide
Deploying to Kubernetes
thoughtbot uses Kubernetes clusters to run containers on AWS. If you’re new to Kubernetes, here are some resources to get you started when deploying your application to a cluster.
Introduction to Kubernetes
Kubernetes is a container orchestration platform. Kubernetes consists of several components:
- An object store for declaring Kubernetes resources
- The Kubernetes API, which allows clients to read and modify resources
- Controllers, which are containers that use the Kubernetes API to watch and update resources and make changes to your infrastructure to reflect resources
- The Kubelet, which runs containers on nodes
Controllers and Resources
Developers create Kubernetes resources to describe how their application should run in the cloud. Kubernetes controllers watch these resources to make infrastructure reflect these resources.
Controllers can create or modify other resources based on the resources they watch or they can make actual changes to your cloud infrastructure to bring your declarations to life.
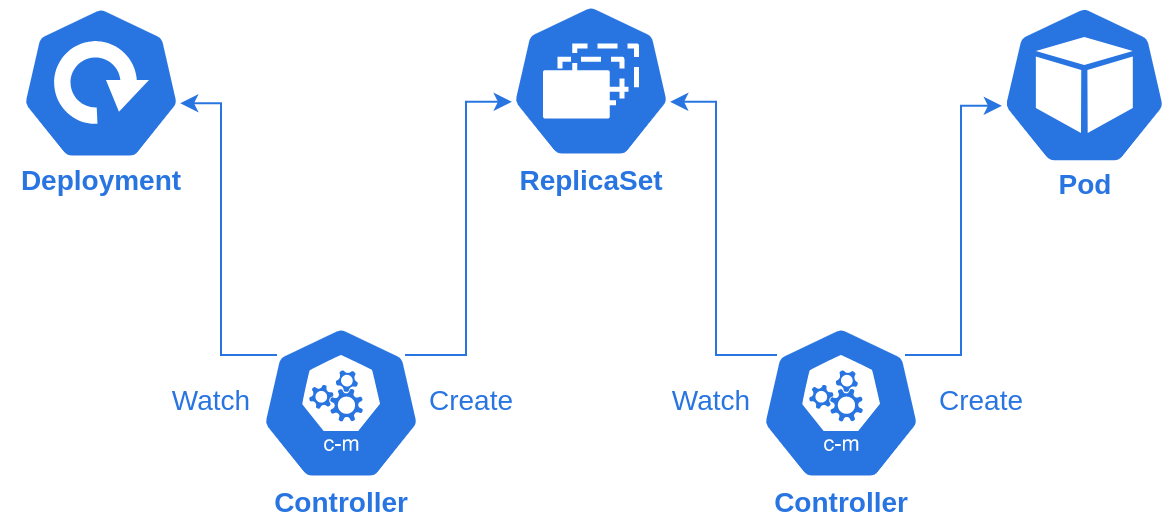
This the above diagram, one controller watches deployments and creates a new replica set for each revision to the deployment. Another controller watches replica sets and creates pods to for each replica set.
Core Resources
There are a few core Kubernetes resources that you’ll interact with as a developer. Kubernetes includes controllers to manage all these resources for you, so all you need to do is declare which resources you need to run your services.
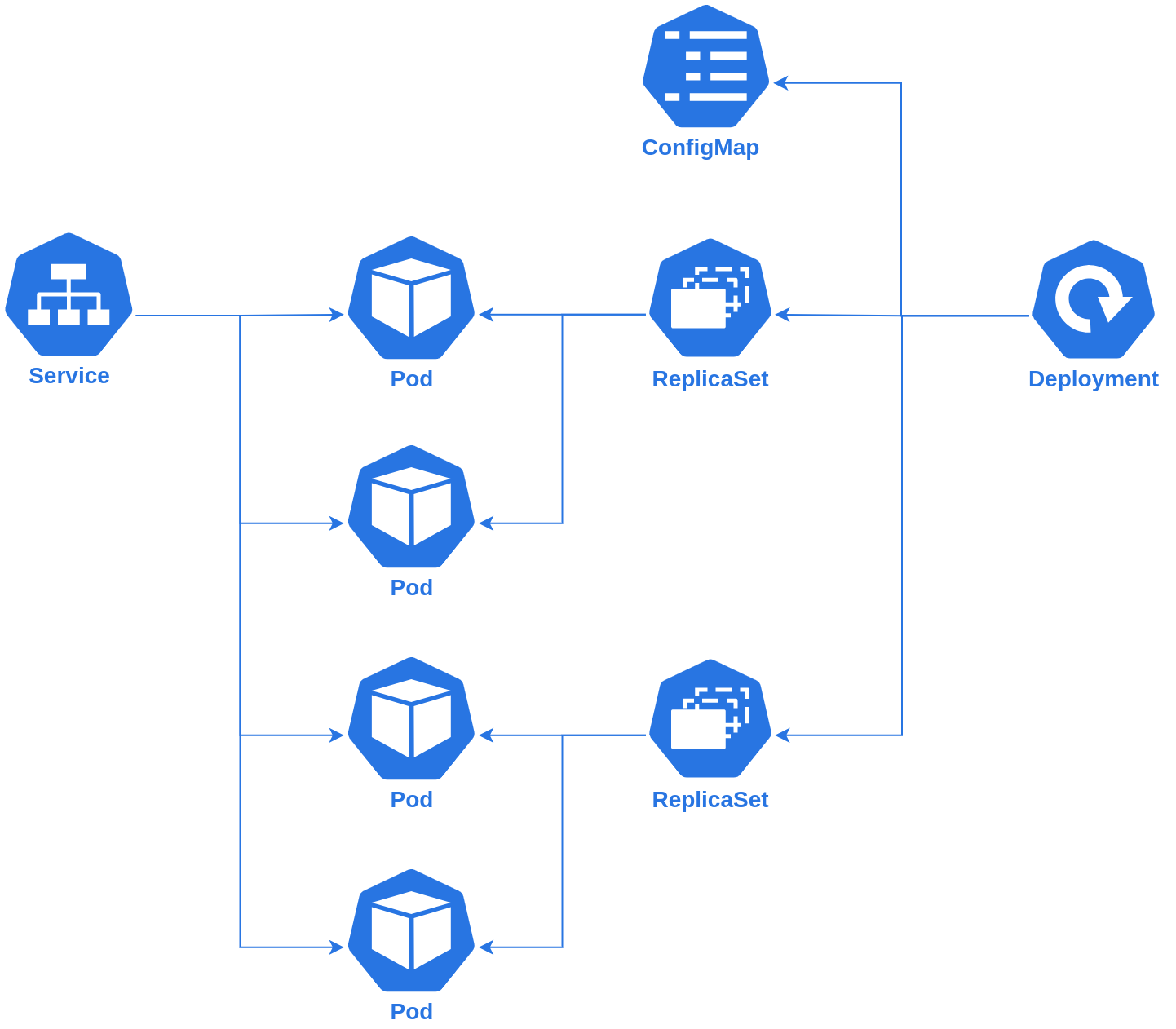
Pods
Pods are the core compute resource in a Kubernetes cluster. A pod is a tightly coupled group of containers working together to provide one unit of work. Some pods may consist of only one container. One example of a pod would be a single instance of a web worker responding to user web requests. In order to fulfill production traffic, you would run several web pods. A pod is similar to a dyno from Heroku.
Kubernetes resources have labels, which are strings that describe the
role of a resource. For example, your web pods might have a
component label with a value of web.
Pods declare a list of containers that will run to complete their work alongside configuration necessary to run those containers. A minimal container definition includes a container image used to create containers in the cluster.
Pods can also declare ports that will be exposed from their
containers. For example, your web pod might declare an http
port listening on port 8080.
Services
A service groups pods together to fulfill a common purpose.
Services find pods based on their labels and optionally describe service ports which will be routed to the appropriate port on each pod.
A web service could select pods with a component label
of web and declare the port 80 for the service
will route to port 8080 on its pods.
Deployments
While a service describe which pods will be used to fulfill a common need, a deployment describes how those pods will run.
A deployment includes labels that will be used to determine which pods it will control as well as a pod template which will be used to create pods for the deployment. A deployment can also declare how many pods will run in order to fulfill requests for the service.
A web deployment would select pods using the component
label of web and include a pod template with the container
image for your application as well as any necessary configuration, such
as environment variables or volumes.
Replica Sets
Each time you modify a deployment, a replica set will be created based on that revision of the deployment. Each time a new replica set is created, it will gradually create pods based on the deployment’s revised pod template until the desired number of pods is created.
Each replica set becomes obsolete when a new replica set is created for its deployment. Once a replica set is obsolete, it will slowly terminate its pods as the new replica set becomes ready until no pods are running for the old replica set.
Config Maps
Config maps can be used to declare environment variables or files that can be mounted in a container. You can create a config map and then use it from several deployments. Config maps are used for non-sensitive information.
Secrets
Secrets work just like config maps except that they’re designed to store sensitive information like passwords. Secrets are mounted as environment variables or files but can have different permissions based on their sensitive nature.
Manifests
To create these resources in a Kubernetes cluster, developers usually author Kubernetes manifests in a Git repository which is automatically applied to the cluster by a CI/CD pipeline.
Authoring Kubernetes Manifests
Kubernetes resources are described by manifests written in YAML.
Every object in Kubernetes has a kind,
apiVersion, and metadata. Most objects also
have a spec.
metadata
Metadata declares information used to identify and find resources.
# Kubernetes objects are versioned and grouped. When objects evolve in ways that
# aren't backwards compatible, they are released as a new version.
apiVersion: apps/v1
# Every Kubernetes object has a kind which declares the type of the resource.
kind: Deployment
metadata:
# Every Kubernetes object has a name, which must be unique within its
# namespace for its kind.
name: example-web
# Labels are used to select relevant resources by deployments and services.
labels:
# Kubernetes has some recommended labels such as name and component.
app.kubernetes.io/component: web
app.kubernetes.io/instance: production
app.kubernetes.io/name: example
app.kubernetes.io/part-of: example
# Kubernetes objects are grouped in namespaces.
namespace: default
# Most objects have a spec that describe the resource being created.
spec:
# ...spec
The spec will vary depending on the kind of object.
For information about deploying services, see deploying services.
Deploying Services
Deploying a service for a pod consists of two resources: a service to describe the service to be provided, and a workload to describe the pods which will fulfill the service. The most common kind of workload is a deployment. You can create services and deployments by authoring Kubernetes manifests.
Services
Services must provide a selector to describe which pods will fulfill this service’s requests. If your service exposes any ports, they will also be described here.
apiVersion: v1
kind: Service
metadata:
# Labels for a service do not need to match its pods, but can overlap.
labels:
app.kubernetes.io/name: example
app.kubernetes.io/component: web
name: example-web
namespace: default
spec:
# Ports describe how the port will be exposed within the cluster as well as
# the port on a pod to which traffic will be routed. If your service doesn't
# expose any ports, this section is not required.
ports:
- name: http
port: 3000
protocol: TCP
targetPort: http
# The selector contains labels which must match for a pod to be considered
# part of this service. These labels will usually be part of the metadata
# section of your pod template in a deployment spec.
selector:
app.kubernetes.io/name: example
app.kubernetes.io/component: web
# If your service doesn't expose ports, you can use None here instead.
type: ClusterIPDeployments
Deployments describe how to create the pods that will run to fulfill a service.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
# Labels for a deployment do not need to match its pods, but can overlap.
app.kubernetes.io/name: example
app.kubernetes.io/component: web
name: example-web
namespace: default
spec:
# The selector contains labels which must match for a pod to controlled by
# this deployment. These labels must contain the selector for a service in
# order to receive traffic for that service.
selector:
matchLabels:
app.kubernetes.io/name: example
app.kubernetes.io/component: web
template:
metadata:
labels:
# The labels for the pod template must include all the selector labels.
app.kubernetes.io/name: example
app.kubernetes.io/component: web
# However, the pod template can also contain extra labels.
app.kubernetes.io/version: stable
spec:
# Your deployment must describe at least one container for its pods.
containers:
# Each container must have a name which is unique within the deployment.
- name: main
# Your containers must include an image. This image can be created as
# part of a CI/CD pipeline, usually using Docker.
image: docker.io/mycompany/myapplication:abcd123
# Your pod templates can include literal environment variables.
- env:
- name: PORT
value: "3000"
# Your pod template can also variables from a config map or secret.
envFrom:
- configMapRef:
name: example
- secretRef:
name: example
# If your pod exposes ports, they must be declared.
ports:
- containerPort: 3000
name: http
protocol: TCP
# You should include a readiness probe so that Kubernetes knows when
# your pods are ready to receive traffic for a service.
readinessProbe:
httpGet:
httpHeaders:
- name: Host
value: example.com
path: /robots.txt
port: 3000
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 2
# If you need to wait for an external condition or perform some special
# work on startup, you can use an init container. These containers use the
# same format as the containers above, but run sequentially before other
# containers start. If an init container fails, it will be retried after
# an incremental backoff period.
initContainers:
# This example container will fail if migrations haven't run yet, which
# means the pod will wait to start up until migrations are complete.
- command:
- rake
- db:abort_if_pending_migrations
envFrom:
- configMapRef:
name: example
- secretRef:
name: example
image: docker.io/mycompany/myapplication:abcd123
name: migrationsEnvironment Variables and Configuration Files
Configuration for pods can provided as environment variables or files by creating config maps and secrets. Both are documents containing key/value data. Config maps are for non-sensitive data. For storing sensitive data like passwords and API tokens, see managing secrets.
Config Maps
Config maps are key/value pairs of string data which can be mounted in a pod as environment variables or as a file.
Environment Variables
You can define environment variables as key/value pairs in a config map:
apiVersion: v1
kind: ConfigMap
metadata:
name: example
namespace: default
data:
APPLICATION_HOST: example.com
LANG: en_US.UTF-8
PIDFILE: /tmp/server.pid
PORT: "3000"
RACK_ENV: production
RAILS_ENV: production
RAILS_LOG_TO_STDOUT: "true"
RAILS_SERVE_STATIC_FILES: "true"You can then mount them in pods by modifying your deployment manifest:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-web
namespace: default
spec:
selector:
matchLabels:
app.kubernetes.io/name: example
template:
metadata:
labels:
app.kubernetes.io/name: example
spec:
containers:
- name: main
envFrom:
- configMapRef:
name: exampleFiles
You can also store a file in a config map and mount it:
apiVersion: v1
kind: ConfigMap
metadata:
name: sidekiq
namespace: default
data:
sidekiq.yml: |
:verbose: false
:concurrency: 10
:timeout: 25You can then mount them in pods by modifying your deployment manifest:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-web
namespace: default
spec:
selector:
matchLabels:
app.kubernetes.io/name: example
template:
metadata:
labels:
app.kubernetes.io/name: example
spec:
# Define your config map as a volume
volumes:
- name: sidekiq
configMap:
name: sidekiq
# Mount the volume in your container
containers:
- name: main
volumeMounts:
- name: sidekiq
mountPath: /app/config/sidekiq.yml
subPath: sidekiq.ymlComposing with Kustomize
Writing Kubernetes by hand can introduce significant data duplication. You may have several deployments using the same image and configuration with slight variations, such as container arguments. You may also use the same configuration in several environments with variations for staging and production. You can use Kustomize to abstract common configuration into bases and apply changes in overlays.
Read more on the Kustomize web site.
AWS Platform Guide
The guide for building and maintaining production-grade Kubernetes clusters with built-in support for SRE best practices.
Source available on GitHub.