Bugs tend to cluster around the boundaries of systems. These can be a great place to start a search for a bug or to focus on catching them proactively in the first place.
Between systems
All sorts of bugs come up when two systems talk to each other. This might be an unexpected edge case like a JSON API that returns HTML for 404 status responses, causing your app to raise an exception.
Systems that deal with user input often get unexpected values. Not only are users unpredictable, HTML forms can trivially be edited to add more fields. Worse, user input can often be downright malicious.
Developers often only think of the happy path when integrating with a 3rd party system. Errors are given minimal thought, so when they inevitably occur they may not get handled the way you’d like.
Within systems
Boundaries don’t just exist between your application and the outside world. There are many boundaries within your app as well.
Business operations need to make certain assumptions about the data they work with. A lot of the work software does is transforming data from untrustworthy and unstructured (such as user input) into more highly structured values so that we can safely perform business operations on it.
This can result in different “zones” in the code that have looser or stricter assumptions about the data. For example:
- Input might start as a raw string from an HTTP request
- It could then be parsed as JSON into a Ruby
Hash - The Hash could then be turned into a
ShoppingCartobject to be processed
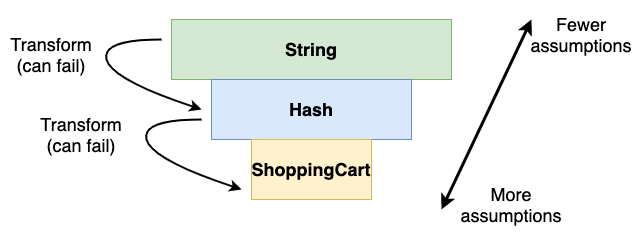
These transitions don’t necessarily happen immediately after each other. The
HTTP handler parts of your code will be happy to deal with a string body and a
Rails controller might be happy to work with a raw Hash.
Where things get tricky are the transitions between these since not all strings are valid Ruby hashes (note that even valid JSON doesn’t always parse to a hash). Not all hashes are valid shopping carts. Boundaries where data transitions from a low-assumption zone to a high-assumption zone are a particularly likely place for bugs to collect.
Implicit Boundaries
Sometimes, your program will switch from a low-assumption context to a high-assumption one without any explicit boundary structures or transitions. This can lead to an implicit boundary in your system.
Primitive obsession is a common cause of this. For
example, in a Rails app that uses raw hashes everywhere, some parts of the code
only care that just a generic hash but in others it assumes that certain keys
like items and total are present. Somewhere between these two parts of the
code you have an implicit boundary.
Detecting
When trying to search for bugs, boundaries can be a great place to start. Drop your print statements here. Rethink the assumptions happening here.
Boundaries tend to be fractal. Break down code into big chunks along major boundaries and each section can then be further sub-divided along its own boundaries. This makes boundaries a good candidate for a binary search approach to finding the source of a bug.
Prevention
Because boundary bugs are such a common type of bug, we have developed a lot of techniques for catching them.
Tests are a great way to discover bugs early. Integration tests allow you to have confidence that sub-systems play nicely together while RSpec’s verifying doubles help make sure the public APIs of different objects stay in sync.
Schemas can be a great tool for detecting and preventing bugs. When building a Rails API, we might have some tests that assert that the output matches a particular json-schema.
Introducing richer value types can help avoid the primitive obsession associated with bugs at implicit boundaries. This can force an explicit transformation step that should check for edge cases and errors. This could be as simple as:
ShoppingCart = Struct.new(:items, :total)
def cart
ShoppingCart.new(Hash.fetch(:items), Hash.fetch(:total))
end
Structure can be a great way to enforce boundaries but not all assumptions can be enforced via structure. Often, you need good old fashioned validation. Checking your assumptions via informal pre and post condition checks or a more formal contract can help avoid nasty surprises. Above all, never trust user input!
Because boundary bugs tend to propagate, it’s often better to fail fast. This
could be as simple as using Hash.fetch or it could involve a manual step like
raising an error in an API endpoint if the generated JSON doesn’t comply
with the published schema.
Depending on the language, we might also be able to get assistance from some form of type-checker built into a compiler or linter.
In production, we might want some kind of logging or telemetry at boundaries so we know when we’re having issues with external systems.
Pay attention to your boundaries
Identifying boundaries can help us detect bugs faster. By proactively giving them care ahead of time, we can help prevent some bugs altogether. As a bonus, we also get code that is less coupled while also being more confident.
Debugging Series
This post is part of our ongoing Debugging Series 2021 and couldn’t have been accomplished without the wonderful insights from interviews with the following people:
