Data modeling is a big part of software design and good models should accurately approximate reality. Ideas from modeling in other disciplines, sets, and an aphorism from the Elm community can help us design better models.
Inspired by a discussion on narrowing types from the Elm discourse.
What is a model?
When we think of the word “model” in software, we often think of the M in
model-view-controller (MVC). If you’re from the Elm community, you might think
of the Model type that stores an application’s state in the Elm Architecture
(TEA).
More broadly, models are simplified constructions that try to approximate and describe reality. A model might be physical, such as a model train or a scale model of a city. It can also be logical, such as a weather model which is a bunch of mathematical equations that try to describe weather systems.

Models in software
What about our models in the software world? They also try to approximate
reality. For example a Registration might try to describe some aspects of a
business process in a vacation booking application.
Real-life customers and processes can be infinitely complex and we can’t capture all of that in our modeling. Instead, we approximate and focus on the characteristics that matter in the context of this particular application.
Model accuracy
Just because all models are approximations doesn’t mean they can’t be accurate.
I find it helpful to think of reality and our model as sets. If we had a perfect model, the set of values our model can describe and the set of values in reality would be identical. If we drew this as a Venn diagram, the two circles would perfectly overlay each other.
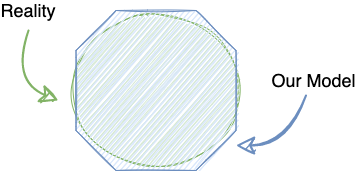
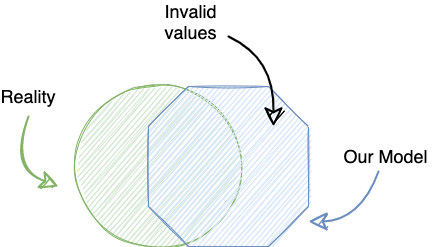
In practice, our models often exclude important details, or more commonly, include values that are not part of the domain we are trying to describe. As programmers, we often label these as “invalid values”.
Modeling flights
For example, as part of modeling a registration process we might ask a customer if they want a one-way or round-trip flight. We might describe this process with two booleans. I’m going to use Elm types to show concrete modeling examples below but the concept applies regardless of your your modeling language.
type alias Flight =
{ roundTrip : Bool
, oneWay : Bool
}
This model is too broad. Reality says there are only 2 kinds of flights: one-way or round-trip and that these two choices are mutually exclusive. However, our model describes 4 different kinds of flights including 2 that are nonsensical (both round-trip and one-way, and neither round-trip nor one-way).
In set terms, we would say that the “reality” set has a cardinality of 2, while the “model” set has a cardinality of 4. Remember, we’re trying to get both sets to be identical so this tells us that our model is too permissive. If our program gets into one of these states, we will likely get garbage output.
We can try and create a different model that better describes the reality of
flight choices. The following can be read as “a Flight is OneWay OR
RoundTrip”
type Flight = OneWay | RoundTrip
Now, both our “reality” and “model” sets have a cardinality of 2 (and both contain the same 2 values). Our model is much more accurate.
Not just types
While the examples in the section above used Elm types, these modeling ideas are not restricted to typed languages. We could do something similar with a Ruby on Rails model as well:
class Flight < ApplicationRecord
enum direction: [:one_way, :round_trip]
end
Making impossible states impossible
Elm programmers often refer to this kind of modeling improvement as “making impossible states impossible”. You’ll often hear this brought up in discussions about what types to use, however the big idea behind it is much broader: align your modeling with the reality you are trying to describe.
More on data modeling
Want to learn more about data modeling? Here are some helpful resources from our blog and around the internet.
