For a new product, you might choose to prioritise speed of development over reliability as you iterate quickly and learn more about your users’ needs. Early adopters may tolerate some instability as the price of rapid innovation. There comes a point in the life of an application, however, when this trade-off is no longer acceptable. For a successful service with many users, unexpected downtime can be extremely costly.
We recently replaced a payment integration for a client with an online ordering system processing tens of thousands of orders per day. Below are some techniques we used to reduce the risks attending this significant change, and to ensure that the migration went smoothly.
Feature flags
Feature flags enable us to test and integrate changes continuously and incrementally, reducing the risk of deploying a single large change in one go. Once a feature is deployed, flags also give us control over when to enable it, and for which users.
Changing the payment provider was a large and complex change, so being able to review and merge smaller changes as we worked made development easier. Using a feature flag to control access to our changes enabled internal users to test them incrementally too. When the time came to enable the new integration, we did so gradually, initially just for 1% of users. This allowed us to monitor the impact of the change whilst carefully managing the risk.
The excellent Flipper gem provides a straightforward means of adding flags to your application, as well as a helpful web UI that can allow admin users to control them.
Design patterns for behaviour variation
A potential downside of feature flags is the need to introduce conditionals throughout your code at points where behaviour will vary depending on the state of the flag. One tactic to minimize this is the use of structural design patterns that enable us to concentrate behaviour variation in fewer places. Such patterns also help us to reduce the number of changes we need to make to our code, reducing the surface for potential bugs.
We were fortunate that the first step in both our legacy and new payment flows was to create a payment session with the provider. This meant that we could use a factory object in our payment sessions controller to determine which provider to use based on the state of the feature flag when the user initiated payment.
# Controller
module Payment
class SessionsController < ApplicationController
def create
@session = SessionFactory.build(current_user)
if @session.save
render json: @session, status: :created
else
head :unprocessable_entity
end
end
end
end
# Factory
module Payment
class SessionFactory
def self.build(user)
if Flipper.enabled?(:new_payment_provider, user)
NewPaymentProvider::Session.new
else
LegacyPaymentProvider::Session.new
end
end
end
end
Later in the flow, when processing payment, we also needed to vary behaviour. Whilst most steps in the process would be common to both providers, capturing the payment itself would clearly vary. Here we were able to use the strategy pattern to inject an object encapsulating the behaviour required to capture payment for a given payment provider into an otherwise generic payment processing service.
class PaymentProcessor
def self.perform(payment_capture_strategy:)
payment_capture_strategy.perform
notify_customer
process_order
end
...
end
Testing
Good test coverage can help reduce the risk of defects making it into production. Introducing feature flags, however, can multiply the code paths that need to be tested, making it harder to ensure adequate test coverage without increasing duplication in the test suite.
The design patterns described above can help with this. Injecting a payment capture strategy into our payment processing service, for example, enables us to easily mock this dependency in our unit tests, removing the need to test behaviour of the service for multiple payment providers.
it "captures payment" do
mock_strategy = double("Payment Capture Strategy")
allow(mock_strategy).to receive(:perform)
PaymentProcessor.perform(payment_capture_strategy: mock_strategy)
expect(mock_strategy).to have_received(:perform)
end
Whilst reducing duplication is helpful, we also found that ensuring we had complete end-to-end test coverage of the legacy payment flow early in the project gave us confidence that the changes we made as we built out the new integration would not introduce a regression.
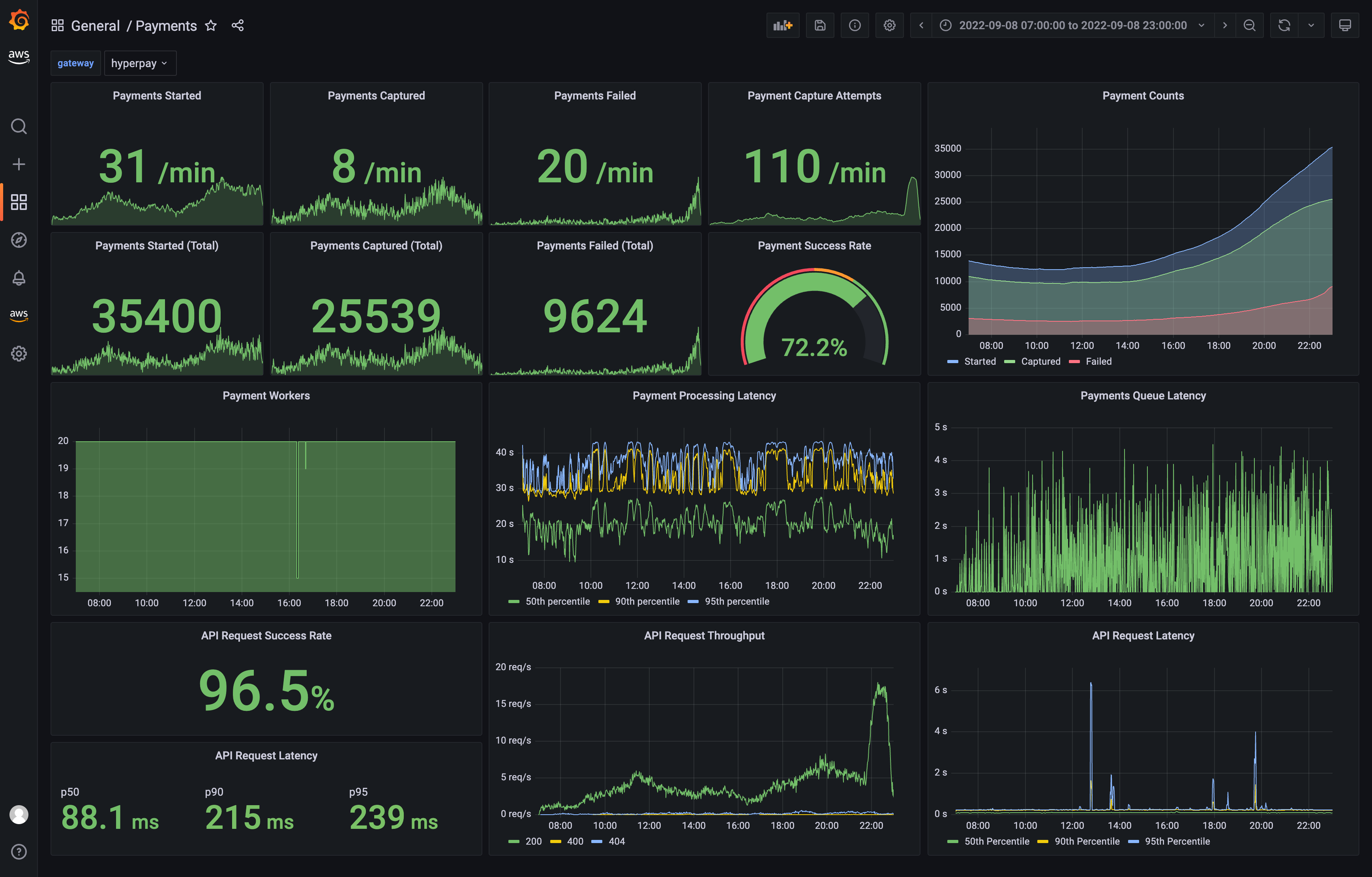
Monitoring
A final practice that further increased our confidence was improving observability of the payment process. We instrumented both technical metrics (payment job and API request latency) and business metrics (payment success rate, payment capture attempts), and visualised these in a Grafana dashboard. As we gradually migrated from legacy to new payment provider, monitoring these metrics reassured us that the system was performing well and that payments were being taken as expected.
Move fast but don’t break things
Adopting the development and release practices described above did not increase the time needed to deliver the payment migration. If anything, they enabled us to move faster by helping us manage complexity and increasing our confidence in our ability to make changes safely. If you need to make a high-risk change to a heavily-used system, these techniques might help you do so safely without sacrificing velocity.