---
title: Classical Reasoning and Debugging
teaser: Classical philosophy offers us multiple reasoning strategies for dealing with
tricky bugs.
tags: debugging,debugging series 2021
author: Joël Quenneville
published_on: 2021-04-30
---
When classical philosophers were thinking about how to think, they started to study
the various ways one can build up a complex argument and prove or disprove an
idea. This birthed the study of **reasoning** and logic as a subject.
They identified some broad categories of ways to think logically. These can form
a helpful framework for us when debugging since it gives us a way to
methodically search for the truth: why is this broken?!!!
There is no definitive list of reasoning types in classical philosophy. Below
are some that I've found particularly helpful in my own experience. I've also
played a bit loosely with the definitions of each type to keep the examples
accessible and useful.
Detail from "The School of Athens" by Renaissance painter Raphael
## Reasoning by analogy
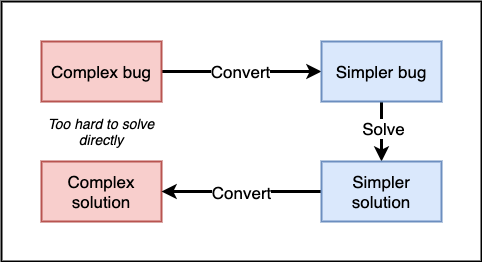
This is one of my favorite approaches! [Reasoning by analogy](https://thoughtbot.com/blog/reasoning-by-analogy) is a 3-step process:
1. Convert your hard problem into an equivalent easier problem (called the
_analog_).
2. Solve the easy problem.
3. Convert the easy solution into a solution for your hard problem.
Process of debugging by analogy
A particularly helpful way to apply this in debugging is reducing a bug to its
[simplest form]. It may not always be obvious what "minimal" means in your
context. That's fine. You can slowly remove pieces of complexity one at time
while verifying that the bug still occurs. Eventually you will be left with a much
smaller piece of code. It should now be easier to find the cause of your bug.
The solution will probably be the same for the full problem.
This can be harder to do when dealing with a bug in a **larger system** rather
than a single file because this class of bug often arises from the interaction
_between_ multiple components. Let's say you are noticing broken behavior in a
Rails application after adding an image manipulation gem. Is the gem broken? Did
you configure it incorrectly? Is some of your other existing code incompatible
with the new gem?
How might you simplify this problem? One way might be to generate a brand new
blank Rails application and add the suspicious gem. If the problem shows up there
you now have a much smaller application to debug. Once you find the solution, it can
be ported back to your real app.
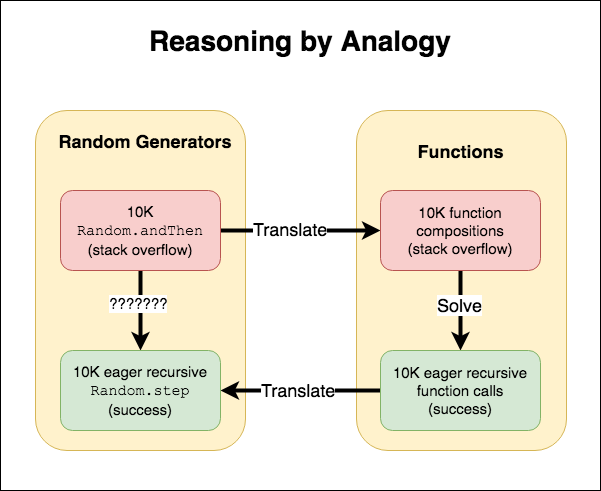
Beyond just simplifying your existing context, analogies allow you to transfer
your bug to a _different_ context that shares some similarities and where you are
better able to debug. For example, in this [Elm debugging tale], I was able to
reproduce a problem when composing random generators to one when composing
functions. I was more familiar with the properties of function composition and
quickly found the source of the bug. Then I back-ported that solution over
to my original random generator problem and was able to solve the issue.
Solving a random generator bug via analogy to functions
[simplest form]: http://sscce.org/
[Elm debugging tale]: https://thoughtbot.com/blog/elm-debugging-story#reasoning-by-analogy
## Process of elimination
Sometimes it's easier to eliminate wrong answers than to find the right one.
Process of elimination falls under the category of abductive reasoning
(oversimplified!).
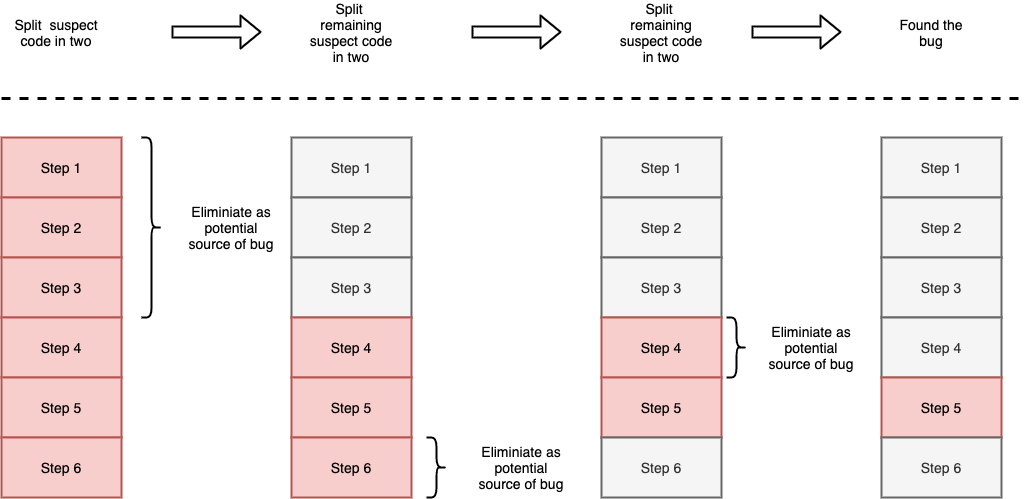
A particularly useful form of this in debugging is a **binary search**. The idea
is that you run a series of experiments to validate if a bug is caused by a
particular piece of code. You design the experiment such that regardless of the
outcome you will be able to dismiss roughly half of the possibilities. Keep
repeating until you find the source of the bug.
Despite the fancy name, this can be done very simply. For example, I am trying
to find a bug that occurs in a particular file. I can use comments or
conditionals to prevent half the file from executing. Can I still reproduce the
bug? If so then I know the bug is in the active half file. If not it must be in
the inactive half of the file. Either way I've eliminated half of the
possibilities and am closer to finding the source of the bug.
Using a binary search approach to locating a bug in a
file
Many programs aren't just a linear set of instructions one after another. We
have conditionals and branching logic leading to a flow that looks more like a
tree than a list. We can still use a binary search approach. Instead of using a
mental model of "splitting the list in half", it can be helpful to think in
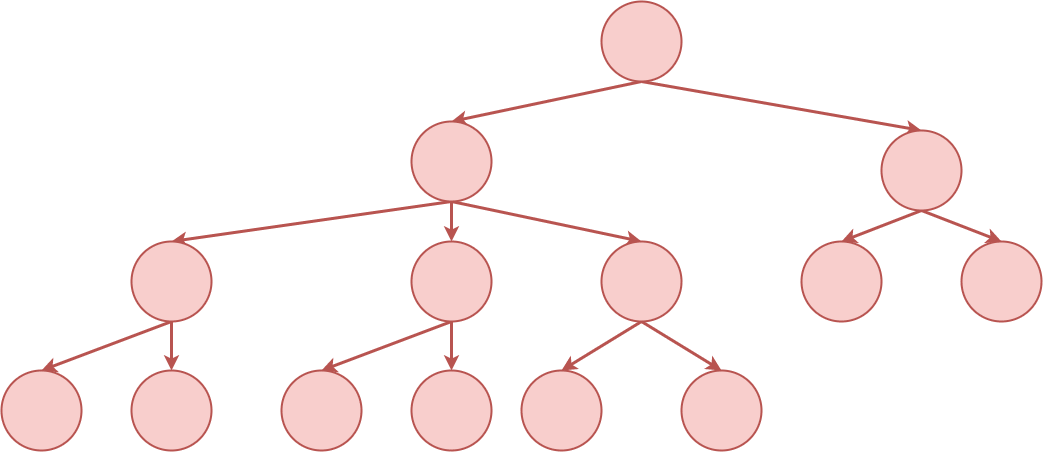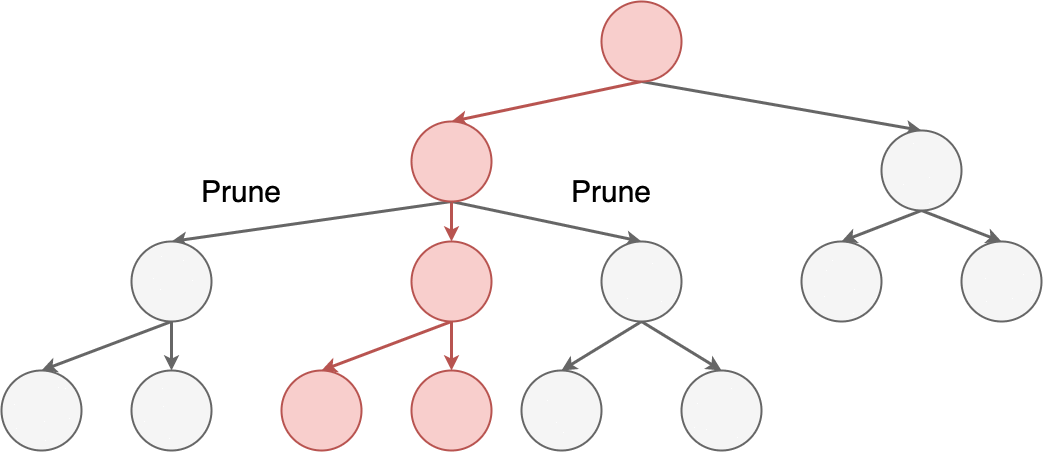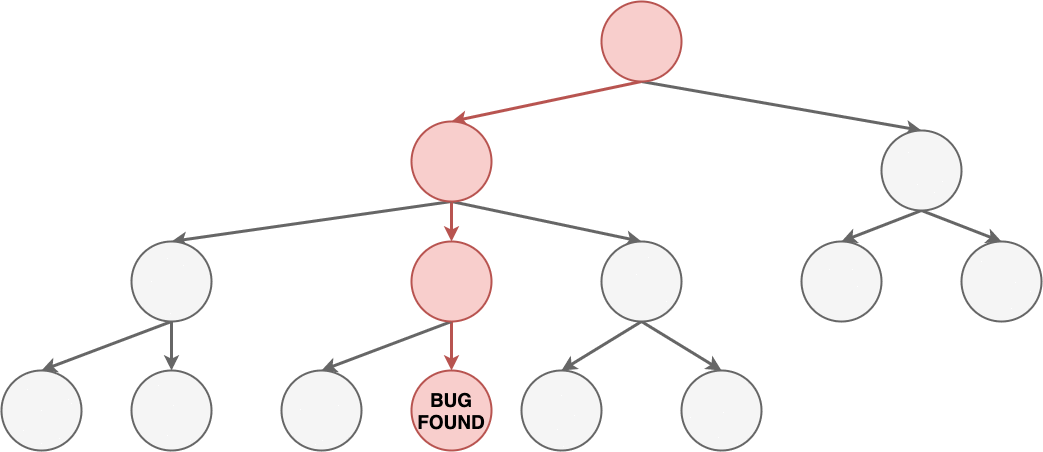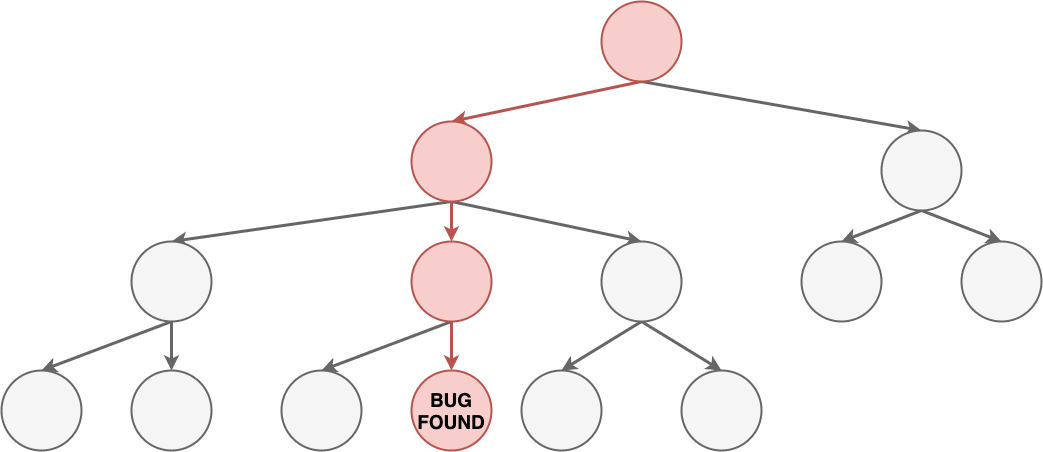
terms of **pruning branches** from the tree. Each branch you can eliminate
narrows the area you need to keep searching for the source of your bug.
Pruning the branches of a decision tree to find a bug
Binary search not only allows you to find bugs in space but also in time!
The [`git bisect`] command lets you use the same approach on your git history to
efficiently find out _when_ a particular bug was introduced.
[`git bisect`]: https://git-scm.com/docs/git-bisect
## Deductive reasoning
This is usually what people think of when talking about "logic" or "reasoning".
We do this in our heads all the time when debugging. Given a series of starting
facts (called _premises_), we build a chain of logic to get to a conclusion.
This might look like:
1. **Given** that Postgres raises a duplicate key error when a uniqueness constraint is
validated
2. **Given** that uniqueness constraints violations only occur on `INSERT` or `UPDATE`
statements
3. **Given** that the only database writes are happening in the `CreateOrderService`
object
4. **Therefore** the error must be happening in the `CreateOrderService` object.
How do we know that? Deductive reasoning is the most mathematical form of
reasoning and can be represented as a sort of equation: `x ⇒ y`, which is read as
"if x then y", or "x implies y".
```
duplicate_error ⇒ index_violation
index_volation ⇒ db_write
db_write ⇒ create_order_invoked
```
There are various mathematical laws that can be applied to these "logic
equations". Some just feel like common sense, others like the [DeMorgan laws]
are not immediately intuitive. If you want to dig into the topic further, the
term you need to search is "[propositional logic]".
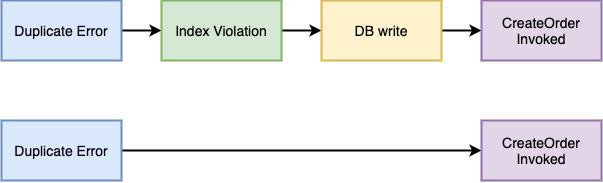
Reducing a chain of if..then premises via the transitive
property
Of particular interest here is the [transitive property]. It states that a long
chain of if..then..then such as `x ⇒ y ⇒ z` can be reduced to a single if..then
`x ⇒ z`. In our example above that means that:
```
duplicate_error ⇒ create_order_invoked
```
Beware a few pitfalls though. If any of your starting premises are wrong then
the whole thing falls apart. In the example above, if there are other files that
also write to the database then our conclusion might be wrong!
A more subtle pitfall is that your intuition may lead you to mis-applying some
of the laws. A particularly common example of this is treating `⇒` as if the
relationship works both ways. Just because an index violation means that a db
write occurred does NOT mean that the reverse is true. DB writes do not imply
that an index violation occurred.
It's really easy to make these errors in your head. Often times the best way to
recover from this sort of mistake is to slow down and [write down your premises]
and how you get to your conclusion. Knowing some propositional logic notation
can be helpful, but plain old prose works too.
---
_Note: There are situations where both sides **do** imply each other. These are
called "biconditional", "if-and-only-if" (or the more condensed "iff") and are
denoted with the double arrow symbol `⟺`._
---
[DeMorgan laws]: https://thoughtbot.com/blog/clearer-conditionals-using-de-morgans-laws
[propositional logic]: https://brilliant.org/wiki/propositional-logic/
[transitive property]: https://www.britannica.com/topic/transitive-law
[write down your premises]: https://thoughtbot.com/blog/debugging-listing-your-assumptions
## Proof by contradiction
Also known as _reductio ad absurdum_ from a Latin phrase meaning "reduction to
the absurd". This is a variation on deductive reasoning, but instead of trying
to prove something true, you try to prove the opposite false.
The process generally looks like this:
Choose an assumption you'd like to prove to be true. Now, assume the opposite of
that is true. Use [deductive reasoning] to make logical conclusions from your
opposite assumption. Arrive at an impossible or absurd conclusion.
The goal is to arrive at a conclusion that can't possibly be true (a
contradiction). Because it cannot be true, your opposite assumption cannot be
true, and thus the original assumption must be true. In propositional logic
notation:
```
P ⇒ Q
¬Q
∴ ¬P
```
What does this look like in practice?
Let's say, you are encountering an error when trying to save bad data from a
form into the database. It can be hard to show deductively _where_ the error is
happening but it's easy to show where it is _not happening_, which, in a
roundabout way, tells us where the error occurs.
You suspect that the error is happening outside the database. Reasoning by
contradiction would try follow the reasoning for the opposite (the error is
happening inside the database) and show that this results in the absurd.
1. **Given** that the data we are trying to save duplicates existing data
2. **Given** that our database has a unique index
3. **Given** that saving duplicate data to the database causes a unique index
exception
4. **Given** that we do not see an unique index exception
5. **Given** that the error occurs in the database (our opposite conclusion)
5. **Therefore** our database does not enforce unique indexes (contradiction)
As with deductive logic, if any of your premises are wrong then your conclusion
may also be wrong. In particular, the assumption that "this could never happen"
is so often wrong. In the example above, our logic would fall apart if it
turned out that there was no unique index on that particular database table.
Oops!
[Test your assumptions!]
[deductive reasoning]: #deductive-reasoning
[Test your assumptions!]: https://thoughtbot.com/blog/debugging-navigating-the-maze#check-it
## Inductive reasoning
Inductive reasoning is used when we look at a bunch of concrete examples and try
to derive a broader principle. This is often the case in debugging. We don't
always have a set of "truths" to reason from. Instead we just have: "in
situation X this strange behavior happens but in situation Y a different strange
behavior occurs".
Having **more sample cases** to reason from is particularly useful. So we try and
reproduce the issues locally. We change some of the inputs and see how that
affects the result. We take copious notes. We may even accumulate logs in
production. Then we try to detect patterns.
The **scientific method** fits under this category and is great way to debug
inductively. It's not for nothing that the 17th century name for science was
"natural philosophy". Once we think we see some patterns, we try and prove our
hunch wrong. We can do this by making a proposed fix and then attempting to
manually reproduce the bug. We can also add some automated test cases to check
a bunch of known ways that trigger the issue. If we consistently fail to trigger
the bug with our changes, our fix is likely correct.
Note that as with science, inductive reasoning doesn't definitely _prove_
anything. Instead it is a best approximation of a correct solution given the
scenarios we had access to. It's possible there are some edge cases we haven't
considered. It's possible our "fix" just masks the symptoms but doesn't fix the
underlying issue. Eventually we might get some more sample cases that show that
we were wrong.
An inductive technique I like to use when I'm stuck is to **"stir the pot"** so
to speak. I throw a bunch of different data at a piece of code and see how it
reacts. I might even make a bunch of semi-random changes to the code itself and
see how that changes the outcome. The goal is not to luck into a solution, but
rather to generate a series of sample cases so I have enough data points to start
seeing patterns.
## The fallacy fallacy
As we've explored each type of reasoning, there have always been pitfalls where
reasoning incorrectly leads us to the wrong path. However, just because your
reasoning is flawed doesn't necessarily mean that your conclusion is wrong. This
is the [fallacy fallacy]. Sometimes you get lucky. Other times your intuition
led you to the right solution even though the logic you used to justify it was
wrong.
Always validate your assumption, premises, and conclusions!
[fallacy fallacy]: https://yourlogicalfallacyis.com/the-fallacy-fallacy
## Putting it all together
The forms of reasoning here are not exclusive to each other. In a typical
debugging session you may want to use all of them together. In fact, even when
reading this article you may have thought that some techniques described pull
from reasoning approaches from other sections. You're not wrong.
We intuitively use all of these reasoning approaches and more every day when we
debug. However, having an explicit understanding of the approaches we are using
allows us to work towards a solution in a more structured manner and avoid
going around in circles. Knowing the pitfalls of the technique we
are using also allows us to stay vigilant and avoid some logical dead-ends.
## Debugging Series
This post is part of our ongoing [Debugging Series 2021] and couldn't have
been accomplished without the wonderful insights from interviews with the
following people:
- [Adam Sharp](https://twitter.com/sharplet)
- [Eebs Kobeissi](https://twitter.com/EebsKobeissi)
- [Eric Bailey](https://twitter.com/ericwbailey)
- [John Schoeman](https://github.com/johnschoeman)
- [Mike Burns](https://thoughtbot.com/blog/authors/mike-burns)
- [Rick Gorman](https://linkedin.com/in/rickgormannyc)
- [Sally Hall](https://github.com/sallyhall)
- [Sam Kapila](https://www.linkedin.com/in/samkap)
- [Sarah Dawson](https://github.com/knittingarch)
- [Sean Doyle](https://github.com/seanpdoyle)
Keep tuning in every week for more great debugging tips.
[Debugging Series 2021]: https://thoughtbot.com/blog/debugging-series-2021-welcome-to-the-jungle